Real Infrastructure
This isn't a demo environment.
This is what I run daily.
GX10 self-built GPU server. 14 models. 22 services. The same infrastructure I use to build your project.
AI Control Center
Real-time monitoring of all 14 LLMs, knowledge base stats (6,021 chunks), resource usage dashboards
Self-hosted GPU Server
NVIDIA GPU running inference locally. CPU/RAM/GPU monitoring. Zero cloud dependency for core inference
Vector Memory System
ChromaDB + nomic-embed-text (768-dim). 6,021 memory chunks. Real semantic search across all knowledge bases
22 Live Services
All running through Cloudflare Tunnel. Uptime monitoring, per-service traffic analytics, zero downtime deployments
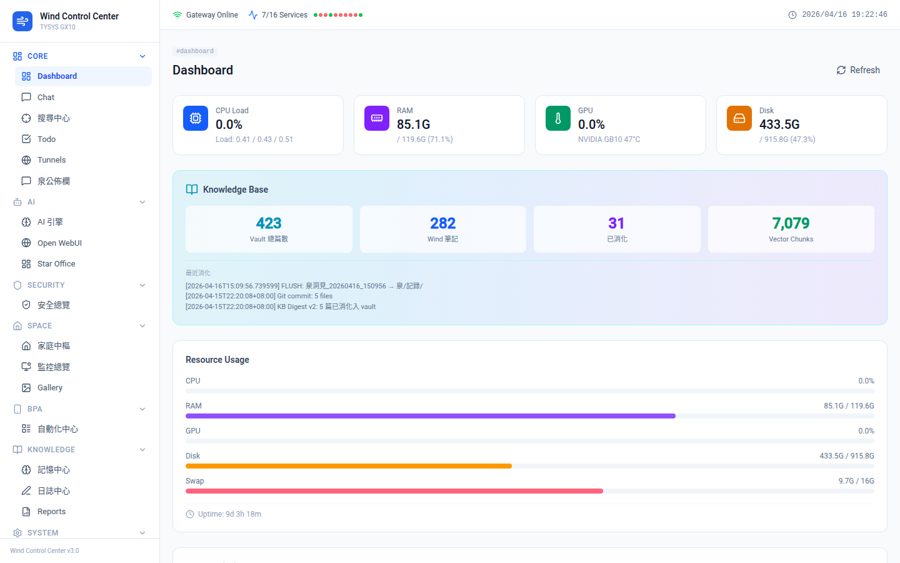
AI Control Center — Live production dashboard
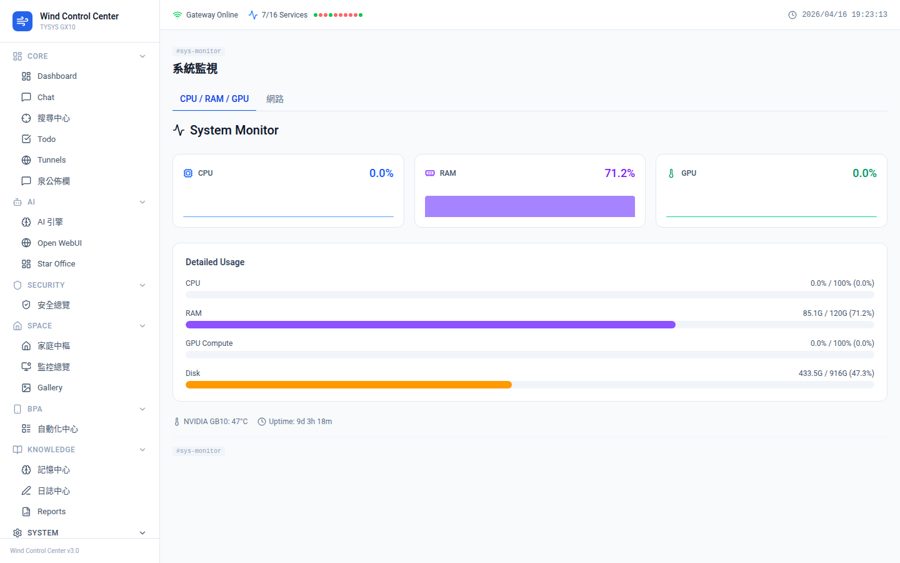
GPU Server Monitor — Real-time inference load